In questo articolo vediamo cos’è la Cross Validation (o Convalida Incrociata) e vediamo come può essere usata nei nostri progetti di Machine Learning.

In uno dei nostri precedenti articoli abbiamo parlato della fondamentale divisione tra train, validation e test. Il nostro set di dati può essere infatti diviso in tre parti che ci serviranno per addestrare il modello e vedere se è in grado di generalizzare con dati nuovi (ovvero su quello di test e validation).
La tecnica di divisione esposta nell’articolo sopra citato è una tecnica statica: suddivido il dataset e quella divisione rimane rigida, costante. Questo è il modo più semplice per valutare un algoritmo di Machine Learning, ma può anche comportare degli inconvenienti.
Cosa succede se in quel 25% casuale di dati che usiamo come test ci sono dei casi limite? Cosa se nel 75% che usiamo come train ci sono dei dati da cui non posso apprendere bene?
una soluzione più dinamica
A questa tecnica statica, possiamo preferire una tecnica più dinamica. La Cross Validation (o validazione incrociata) è infatti una tecnica statistica che permette di usare in modo alternato i dati sia per il train che per il test.
Spesso viene chiamata k-fold cross validation perché diviso il dataset iniziale in una serie di porzioni uguali di dati (k-campi) e ne uso iterativamente un tot per il train e un tot per il test.
Immaginiamo di avere 100 mail nel nostro dataset. Al posto di usarne 75 per addestrare il modello e 25 per testarlo (o valutarlo), divideremo i dati in 5 segmenti da 20 osservazioni. Ne useremo ogni volta 4 per addestrarlo e la restante parte per valutarlo. E questo lo farò finché non avrò usato ogni parte di dati per addestrare e per valutare il modello e i suoi risultati.
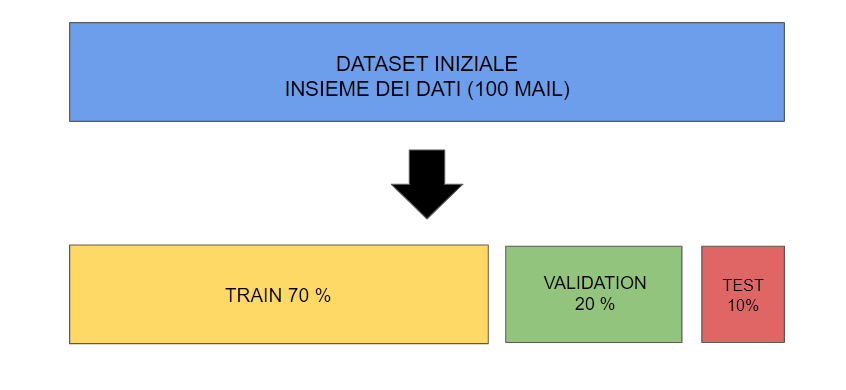
La versione statica quindi segue una struttura del genere:
La k-fold cross validation segue invece la logica dinamica di cui abbiamo parlato, con uno schema come quello riportato nell’immagine qui sotto:

Nella Cross Validation si vede bene come ogni volta utilizzo porzioni diverse per il train e per il test. Il train è rappresentato naturalmente dalla parte blu, mentre il test da quella color ocra (sì secondo me è ocra, né giallo né arancione).
In questo modo sono in grado di limitare i danni nel caso di dati sporchi sia nel test sia nel train. Il risultato finale sarà poi una media delle performances delle varie iterazioni.
Non c’è da preoccuparsi se le performances cambieranno da iterazione a interazione, è proprio quello il senso di usare ogni volta dati differenti per addestrare e valutare il nostro modello.