In questo articolo ti parlo di 3 package di XAI in Python, ognuno accompagnato da un bel po’ di codice!

Hai mai sentito parlare di XAI?
XAI è l’acronimo di eXplainable Artificial Intelligence, ed è quel campo di ricerca che mira a rendere più interpretabili i modelli di Machine Learning e Deep Learning.
Una delle critiche che viene maggiormente mossa a questi modelli è il fatto di essere delle black-box, delle scatole nere.
Strumenti potenti, potentissimi, ma poco trasparenti e comprensibili.
Ed effettivamente in molti casi è così: quanto più un modello è complesso, tanto più è difficile da interpretare.
Difficili da interpretare non vuol dire però impossibili!
Chi lavora in questo ambito e ne conosce il funzionamento sa benissimo infatti che questi algoritmi, per quanto complessi, non sono imperscrutabili. Sono frutto di calcoli matematici e algoritmi informatici e in quanto tali sono in realtà interpretabili e comprensibili.
In questo articolo ti parlo di 3 interessantissimi progetti di XAI in Python che aiutano a trasformare queste scatole nere in scatole bianche, oggetti sicuramente più facili da interpretare!
Prima di iniziare, ti consiglio di dare un’occhiata all’articolo in cui approfondisco il tema della XAI su Pulp Learning, e ti consiglio anche il mio profilo LinkedIn e Medium, dove parlo spesso di questi temi.
XAI in Python
Esistono molti progetti di XAI in Python che soprattutto negli ultimi anni stanno popolando i server di GitHub.
In questa guida mi concentro su 3 progetti che per ragioni diverse sono quelli più interessanti nell’ambito dell’eXplainable Artificial Intelligence.
Sicuramente non sarà una lista esaustiva ma spero risulti lo stesso interessante!
Ho selezionato questi progetti:
Per i tutorial utilizzeremo Google Colab, che permette di eseguire facilmente e gratuitamente codice Python online.
SHAP
SHAP, che sta per SHapley Additive exPlanations, è la libreria più utilizzata libreria utilizzata per spiegare il funzionamento dei modelli di Machine Learning e Deep Learning.
Si basa sul concetto di valutare il contributo di ciascuna variabile nel modello per fare predizioni specifiche. Utilizza l’approccio di valore di Shapley dalla teoria dei giochi per stimare l’importanza di ogni caratteristica attraverso diverse iterazioni.
SHAP fornisce spiegazioni individuali per le previsioni del modello, aiutando gli utenti a comprendere come ciascuna variabile ha influenzato il risultato.
E’ molto utile quando si tratta di modelli di Machine Learning basati sugli alberi decisionali e sulle reti neurali.
Per prima cosa dobbiamo installare il package. Eseguiamo nella cella del Notebook:
!pip install shapA questo punto importiamo le librerie che ci interessano, come per esempio xgboost per addestrare un modello e lo stesso shap per interpretarlo.
import xgboost
import shapAddestriamo un modello sfruttando i dataset di shap:
X, y = shap.datasets.california()
model = xgboost.XGBRegressor().fit(X, y)Utilizziamo l’explainer di shap per creare il modello interpretabile e creiamo gli shap_values, ovvero i valori di shap che ci aiuteranno a rendere più comprensibile il modello di ML.
explainer = shap.Explainer(model)
shap_values = explainer(X)A questo punto possiamo utilizzare il modulo plots di shap per creare grafici di XAI in Python. Tramite bar possiamo avere l’importanza di ogni variabile per il modello.
shap.plots.bar(shap_values)
Il grafico che a mio avviso è il più importante è quello che si ottiene tramite shap.summary_plot(shap_values), in questo grafico possiamo vedere come cambi l’impatto delle variabili sul target a seconda del valore reale della feature analizzata.
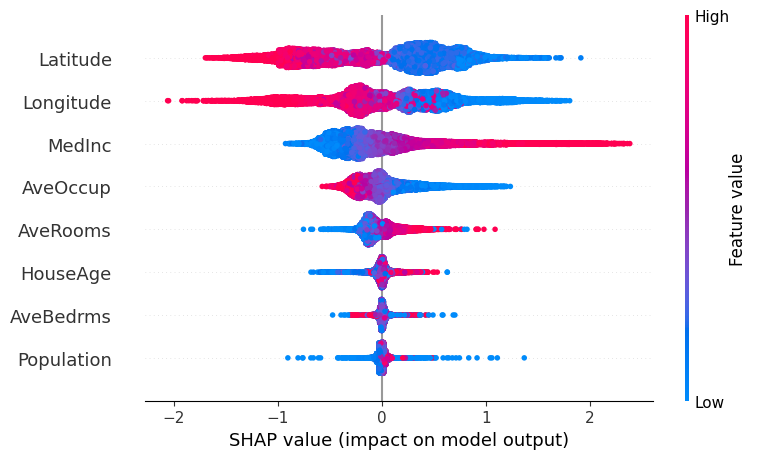
Per maggiori dettagli, dai un’occhiata alla documentazione.
LIME
Dopo SHAP, arriviamo alla seconda libreria più famosa in ambito XAI, ovvero LIME.
Questo progetto ha ben 11k stars su GitHub, anche se negli ultimi anni mi sembra un po’ trascurato da parte degli sviluppatori.
LIME, che sta per Local Interpretable Model-agnostic Explanations, si concentra sull’interpretazione locale dei modelli di Machine Learning. Rispetto a SHAP infatti qui l’approccio è locale, mentre nel caso precedente si utilizza un approccio globale al modello.
LIME funziona generando spiegazioni interpretabili per le previsioni del modello, concentrandosi su un’istanza di dati specifica anziché sull’intero modello.
Questo approccio coinvolge la generazione di campioni di dati “vicini” all’istanza di interesse e l’addestramento di un modello interpretabile (come un albero decisionale o una regressione lineare) su questi campioni. Le previsioni di questo modello interpretabile vengono quindi utilizzate come spiegazioni per la previsione del modello originale.
Anche in questo caso, procedi all’instazione del package tramite il comando pip install lime nel notebook.
Per questo caso utilizzeremo anche sklearn, una famosissima lib di Machine Learning di cui ti ho parlato anche qui.
import lime
import lime.lime_tabular
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_splitAnche in questo caso, creiamo i dati di train e di test e addestriamo il modello.
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=77)
model = RandomForestClassifier(n_estimators=100, random_state=77)
model.fit(X_train, y_train)A questo punto possiamo utilizzare l’explainer di LIME, che svolge una funzione simile a quello di shap.
explainer = lime.lime_tabular.LimeTabularExplainer(X_train, feature_names=iris.feature_names, class_names=iris.target_names, discretize_continuous=True)Poiché LIME lavora in modo locale, scegliamo un’istanza di test da testare e poi visualizziamo la spiegazione tramite LIME.
instance = X_test[0]
explanation = explainer.explain_instance(instance, model.predict_proba, num_features=4)
explanation.show_in_notebook()LIME mi restituirà principalmente 3 grafici.
Prediction Probabilities

Not class vs Yes class

Features Values

Qui puoi trovare maggiori informazioni dalla documentazione del progetto.
IntrerpetML
L’ultimo package di XAI in Python che ti faccio vedere oggi è InterpretML, un progetto open source che incorpora lo stato dell’arte delle tecniche di XAI.
Una delle funzionalità più interessanti di questa libreria è il suo EBM, ovvero l’Explainable Boosting Machine.
Il modello Explainable Boosting Machine (EBM) è un algoritmo interpretabile che offre spiegazioni chiare e intuitive delle sue predizioni. Gli EBM sono modelli basati su alberi di regressione che approssimano le funzioni di risposta complesse, mantenendo comunque una facile interpretazione.
Questo modello permette di fornire sia spiegazioni locali, sia spiegazioni globali, facendo un po’ una sintesi tra i due approcci precedentemente discussi, guidati rispettivamente da LIME (locale) e SHAP (globale).
Installiamo la librerie e importiamo i package necessari:
!pip install interpret
from interpret import set_visualize_provider
from interpret.glassbox import ExplainableBoostingClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_splitCreiamo x e y:
data = load_breast_cancer()
X = data .data
y = data .target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=77)A questo punto, addestriamo il famoso EBM per un caso di classificazione.
ebm = ExplainableBoostingClassifier()
ebm.fit(X_train, y_train)Usiamo il modello per fare predizioni e visualizziamo le spiegazioni globali del modello creato.
predictions = ebm.predict(X_test)
ebm_global = ebm.explain_global()
ebm_global.visualize()
Puoi trovare maggiori informazioni nella documentazione ufficiale.
Conclusioni sulla XAI in Python
In questo articolo ti ho parlato di 3 progetti di XAI in Python che secondo me sono molto interessanti.
Questo ambito di ricerca sta diventando acquistando sempre più rilevanza ed è molto importante conoscerlo ed utilizzarlo.
Tra i package di cui ti ho parlato, il più importante e completo è sicuramente SHAP, che sta cercando sempre di più di evolvere la propria capacità analitica e grafica.
Gli altri sono comunque progetti importanti: LIME è storico anche se forse un po’ più obsoleto, mentre InterpretML sta crescendo rapidamente e al momento è molto supportato.
Ti ringrazio se sei arrivato fin qui e spero di rivederti presto!